Benchmarks¶
This page records benchmark results for Rasteret's index-first reads against
TorchGeo/rasterio, Google Earth Engine, and Hugging Face datasets baselines.
Treat the exact numbers as environment-specific; the useful signal is where
time is spent in each workflow.
The TorchGeo comparison follows the workflow in
docs/tutorials/05_torchgeo_benchmark_rasteret_vs_rasterio.ipynb.
Environment: Ubuntu Linux, Python 3.13, us-west-2 EC2 instance.
Data source: Sentinel-2 L2A via Earth Search v1, with COGs on S3 in us-west-2.
Controlled variables: same scenes, AOIs, sampler, DataLoader, and
stack_samples collate path. Both paths output the same
[batch, T, C, H, W] tensor shape.
TorchGeo runs with GDAL settings based on Pangeo COG best practices:
GDAL_DISABLE_READDIR_ON_OPEN = "EMPTY_DIR"
AWS_NO_SIGN_REQUEST = "YES"
GDAL_MAX_RAW_BLOCK_CACHE_SIZE = "200000000"
GDAL_SWATH_SIZE = "200000000"
VSI_CURL_CACHE_SIZE = "200000000"
TorchGeo / rasterio Baseline¶
TorchGeo's native path reads remote COGs through GDAL/rasterio. Rasteret reads the pre-built collection metadata and fetches only pixel byte ranges.
Cold start:
| Scenario | TorchGeo/rasterio | Rasteret | Speedup | Shape |
|---|---|---|---|---|
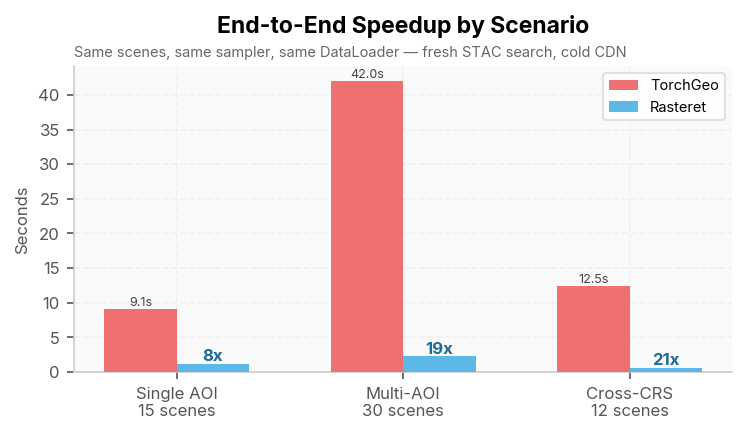
| Single AOI, 15 scenes | 9.08 s | 1.14 s | 8.0x | [2, 15, 1, 256, 256] |
| Multi-AOI, 30 scenes | 42.05 s | 2.25 s | 18.7x | [4, 30, 1, 256, 256] |
| Cross-CRS, 12 scenes | 12.47 s | 0.59 s | 21.3x | [2, 12, 1, 256, 256] |
Warm cache, immediate re-run:
| Scenario | TorchGeo/rasterio | Rasteret | Speedup | Shape |
|---|---|---|---|---|
| Single AOI, 15 scenes | 9.14 s | 0.81 s | 11.3x | [2, 15, 1, 256, 256] |
| Multi-AOI, 30 scenes | 29.68 s | 2.60 s | 11.4x | [4, 30, 1, 256, 256] |
| Cross-CRS, 12 scenes | 3.61 s | 1.06 s | 3.4x | [2, 12, 1, 256, 256] |
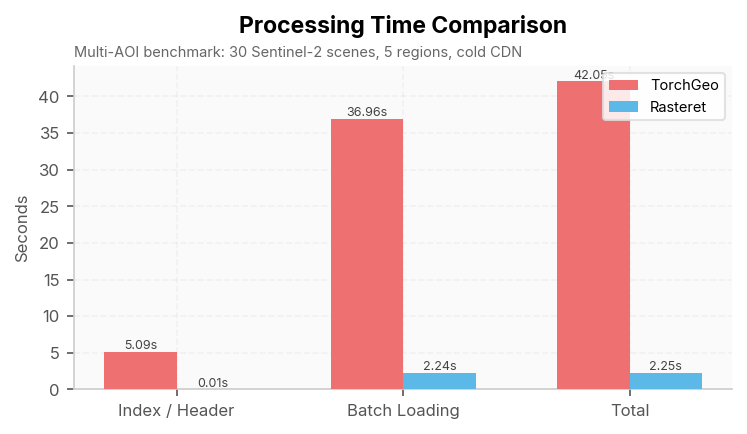
Where The Difference Comes From¶
| Step | TorchGeo/rasterio path | Rasteret path |
|---|---|---|
| Index/header metadata | rasterio.open() per COG over HTTP |
Pre-built Parquet collection metadata |
| Time-series read | Sequential rasterio.merge() per timestep |
Timesteps/bands fetched with asyncio.gather |
| HTTP per timestep | Header + pixel ranges | Pixel ranges, because headers are cached |
| Concurrency | Mostly sequential in this benchmark path | Concurrent byte-range reads |
Index/header time means:
- TorchGeo/rasterio: time spent opening remote files and parsing TIFF IFD metadata over HTTP.
- Rasteret: time to read the pre-built collection index from local storage.
Google Earth Engine / Time-Series Baseline¶
This separate time-series comparison measures Rasteret against Google Earth Engine and a thread-pooled rasterio path:
| Library | First run (cold) | Subsequent runs (hot) |
|---|---|---|
| Rasterio + ThreadPool | 32 s | 24 s |
| Google Earth Engine | 10-30 s | 3-5 s |
| Rasteret | 3 s | 3 s |
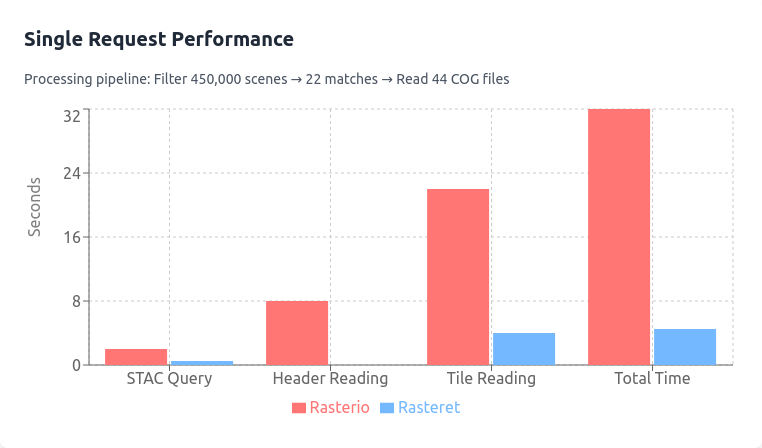
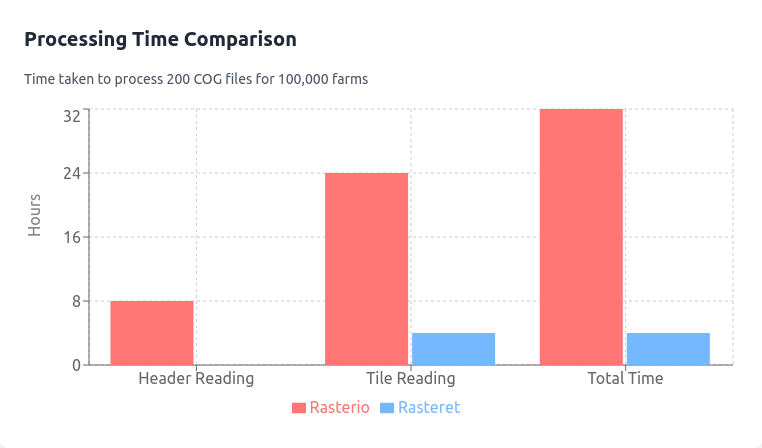
Hugging Face datasets Baseline¶
This benchmark compares Rasteret with image-bytes-inside-Parquet workflows using
Hugging Face datasets and Major TOM-style keyed patch access.
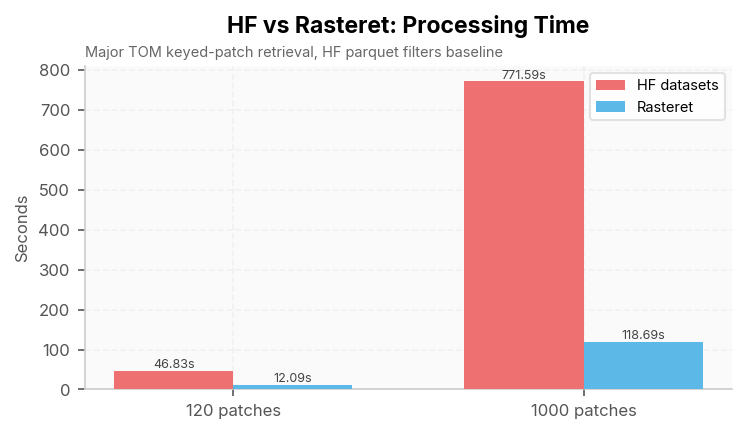
| Patches | HF datasets parquet filters |
Rasteret index + COG | Speedup |
|---|---|---|---|
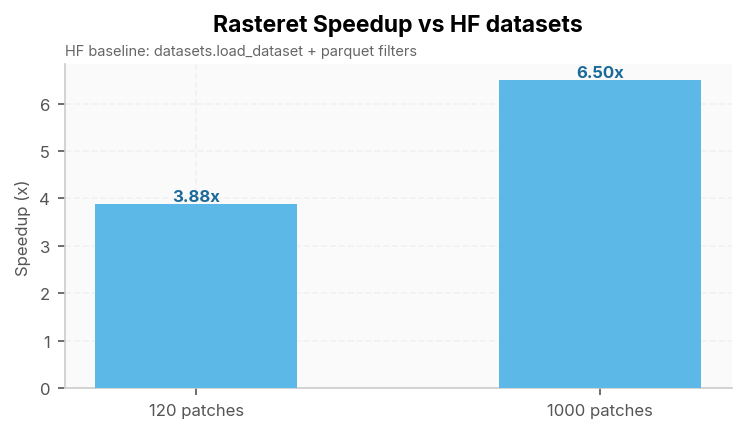
| 120 | 46.83 s | 12.09 s | 3.88x |
| 1000 | 771.59 s | 118.69 s | 6.50x |
The point is not that images-inside-Parquet is never useful. It is that for large cloud COG collections, Rasteret can keep pixels in the published COGs and use Parquet as the queryable index.
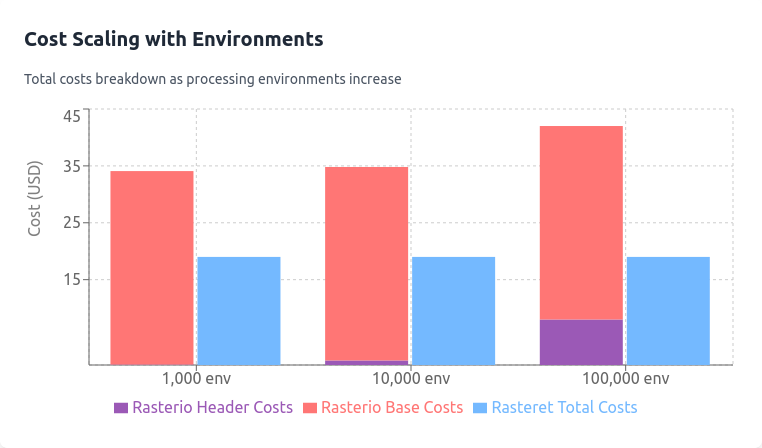
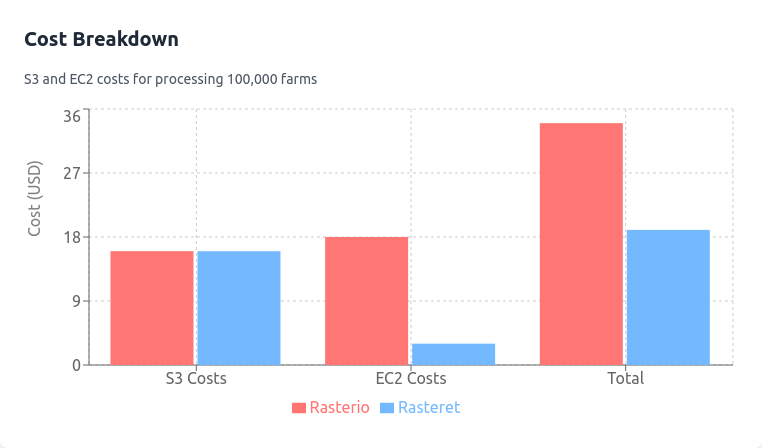
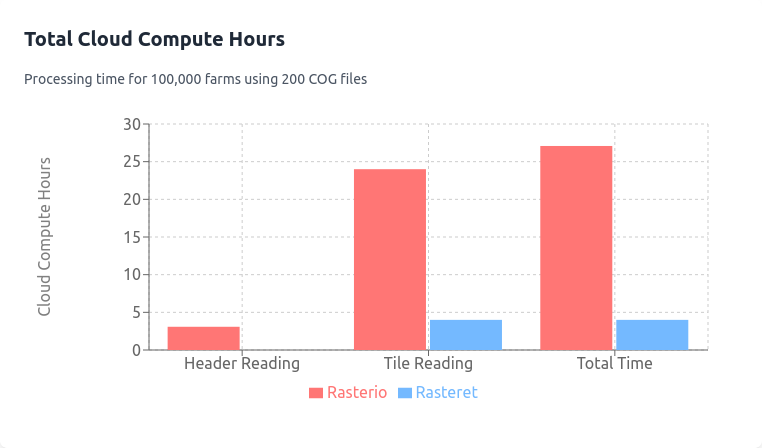
Cost And Scaling Views¶
The following figures summarize supporting cost/scaling views from the same benchmark asset set.
Reproducibility¶
# Fresh run
uv run python -m nbconvert --execute docs/tutorials/05_torchgeo_benchmark_rasteret_vs_rasterio.ipynb
# Immediate re-run
uv run python -m nbconvert --execute docs/tutorials/05_torchgeo_benchmark_rasteret_vs_rasterio.ipynb
Results vary with network conditions, instance placement, cloud credentials, and provider rate limits.
Why Cold Starts Matter¶
Every new notebook kernel, VM, Kubernetes pod, CI runner, or colleague's fresh environment starts cold. In the rasterio/GDAL path, remote COG headers are re-read to discover tile offsets and byte counts. Rasteret stores that header metadata in the collection, so repeated reads can start from the cached index and go straight to pixel byte ranges.
If you run Rasteret on bigger collections, different sensors, or production pipelines, share timings in GitHub Discussions or Discord.